Sciencemag.cz
Sciencemag.cz

Related Articles



Strojové učení dnes nalézá uplatnění v nejrůznějších oblastech lidské činnosti počínaje ekonomií a energetikou přes průmyslovou automatizaci, robotiku a automobilový průmysl až po biomedicínu či oblast zábavního průmyslu a multimedií. MATLAB, jakožto vývojové prostředí pro vědeckotechnické výpočty, nabízí v oblasti strojového učení množství algoritmů a usnadní jejich aplikaci při řešení praktických úkolů.
„Strojové učení je podoblastí umělé inteligence, zabývající se algoritmy a technikami, které umožňují počítačovému systému „učit se“. Strojové učení se značně prolíná s oblastmi statistiky a dobývaní znalostí a má široké uplatnění … “ (Wikipedia).
Příkladem uplatnění strojového učení v praxi je oblast výpočetních financí (úvěrové bodování, algoritmické obchodování), výpočetní biologie (výzkum léků, sekvencování DNA), energetika (předpovídání spotřeby a vývoje cen), počítačové zpracování přirozeného jazyka, rozpoznání řeči a obrazu, reklama a propagace, a mnoho dalších (obr. 1).
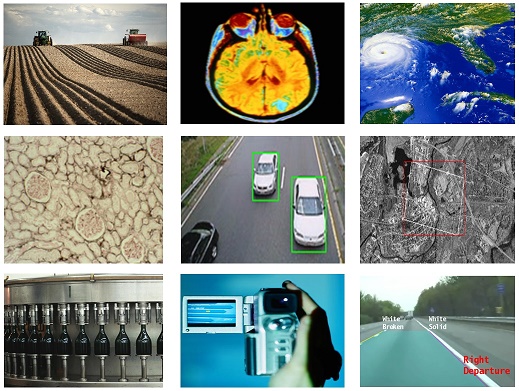
Obvyklé oblasti aplikace strojového učení
Co je strojové učení
Strojové učení používá data a vytváří program k plnění zadaného úkolu. Jádrem výsledného programu je matematický model, který vyhodnocuje výstupy na základě vstupních dat. Úkolem strojového učení je nastavení parametrů modelu tak, aby vyhodnocení výstupů probíhalo s maximální přesností a minimem chybných výsledků.
Strojové učení lze rozdělit do dvou skupin. Učení s učitelem vyžaduje sadu trénovacích dat, kde je vstupním datům explicitně přiřazen správný výstup. Algoritmus strojového učení využije trénovací data k naučení vnitřního modelu. Naučený model je následně využíván k odhadu výstupu pro nové hodnoty vstupů. Pokud nejsou trénovací data k dispozici, je možné využít přístup učení bez učitele.
Základními úlohami strojového učení jsou klasifikace, regrese a shluková analýza. Klasifikace využívá matematický model k rozdělení objektů popsaných vstupními daty do dvou či více tříd. Regrese spočívá v odhadu spojité výstupní veličiny na základě vstupních dat. Shluková analýza hledá v datech přirozená seskupení na základě podobných vlastností.
Zatímco klasifikace a regrese spadají do oblasti učení s učitelem, shluková analýza je typickým příkladem učení bez učitele (obr. 2).
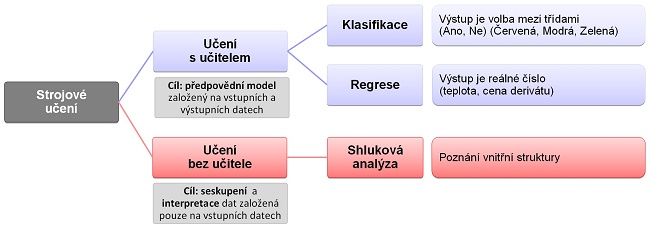
Rozdělení strojového učení podle typu úlohy
Strojové učení a MATLAB
MATLAB je integrované prostředí pro vědeckotechnické výpočty, modelování, návrhy algoritmů, simulace, analýzu a prezentaci dat. MATLAB je nástroj jak pro pohodlnou interaktivní práci, tak pro vývoj širokého spektra aplikací.
MATLAB poskytuje funkce pro všechny hlavní úlohy v oblasti strojového učení: klasifikaci, regresi i shlukovou analýzu.
a) Klasifikace
Cílem klasifikace je zařazení objektů do disjunktních tříd. Objekty jsou popsány datovými hodnotami (vlastnosti objektu), které jsou vstupem do klasifikačního algoritmu, klasifikátoru.
MATLAB poskytuje celou škálu klasifikačních algoritmů. Jsou to rozhodovací stromy, diskriminační analýza (LDA, QDA), algoritmus podpůrných vektorů (support vector machines – SVM), naivní bayesovský klasifikátor či algoritmus k-nejbližších sousedů. Dále lze využít obecnější přístupy, jako neuronové sítě, fuzzy logiku a další.
Práce s klasifikátory v MATLABu je velmi snadná, protože ačkoliv se jedná a značně odlišné algoritmy, MATLAB nad nimi poskytuje jednotné rozhraní. Uživatel si nejprve vybere typ klasifikátoru. Klasifikátor vytvoří a naučí funkcí fit doplněnou jménem klasifikátoru (např. fitctree pro klasifikační strom). Klasifikační model je vytvořen jako objekt v pracovním prostoru MATLABu. Pro následnou klasifikaci nových dat slouží funkce predict, bez ohledu na typ klasifikátoru. Samozřejmostí je možnost nastavení různých parametrů, které chování klasifikačních algoritmů ovlivňují.
MATLAB navíc poskytuje přehledné grafické uživatelské rozhraní, Classification Learner App (obr. 3). Tato aplikace umožní výběr dat, volbu klasifikátorů, jejich nastavení a učení. Také poskytuje přehlednou vizualizaci výsledků včetně metrik pro porovnání jednotlivých klasifikátorů mezi sebou. Takto lze projít celým procesem učení klasifikátoru až po výběr nejlepšího kandidáta bez nutnosti programování. Výsledný klasifikátor lze pak snadno aplikovat na nová vstupní data.
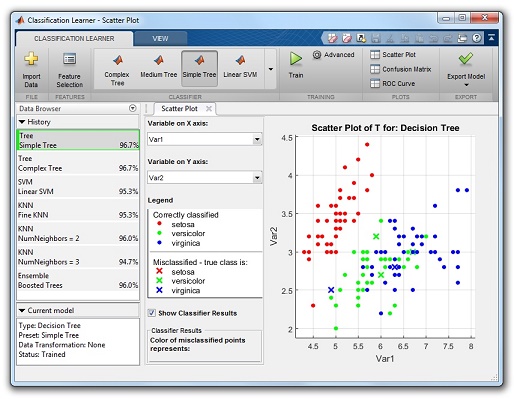
Grafická aplikace Classification Learner pro učení a správu klasifikátorů
b) Regrese
Cílem regresní analýzy je odhad spojité výstupní veličiny na základě vstupních dat. MATLAB poskytuje algoritmy pro lineární regresi, nelineární regresi a zobecněnou lineární regresi (lineární regresní model doplněný nelineární spojovací funkcí).
Pro vytvoření a učení regresních modelů lze využít funkce fitlm, fitnlm a fitglm, případně funkci stepwise pro regresi s postupným přidáváním členů. Odhad výstupu z nových vstupních dat opět zajišťuje funkce predict.
c) Shluková analýza
Cílem shlukové analýzy je rozdělení dat do skupin na základě podobných vlastností. MATLAB poskytuje funkce, jako je hierarchická shluková analýza, algoritmus k-means, směs Gaussových rozdělení, samo-organizující se sítě, algoritmus fuzzy c-means, skryté Markovovy modely a další.
Aplikace strojového učení krok za krokem
Aplikace využívající strojové učení obvykle sestávají ze dvou fází – fáze učení, kdy je určen výsledný model pro klasifikaci či regresi, a fázi predikce, kdy je model nasazen na nová data pro odhad výstupu nebo zařazení nových dat do správné kategorie (obr. 4).
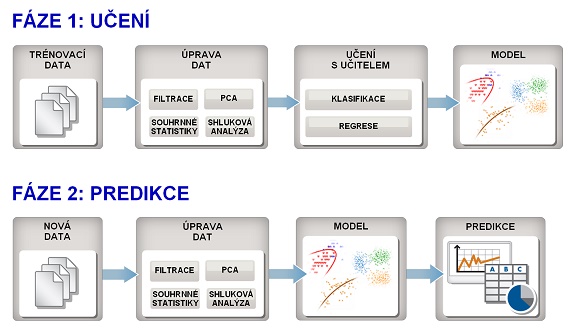
Posloupnost kroků při strojovém učení
Aplikace metod strojového učení však nespočívá pouze v hledání samotného klasifikátoru či regresního modelu, ale také ve vhodné přípravě dat. Data se nejprve vhodným způsobem upraví a teprve poté jsou předána na vstup klasifikačního nebo regresního modelu. Surová neupravená data lze přímo využívat jen velmi zřídka.
Někdy postačuje data před vstupem do modelu filtrovat a zbavit je tak nežádoucího šumu. Pokud data sestávají z přílišného množství veličin, je možné využít analýzu hlavních komponent (PCA) a převést mnoharozměrová data do jednodušší podoby. Také není vždy nutné, aby model pracoval se všemi datovými vzorky, postačí pouze použít souhrnné statistické údaje za stanovaný časový úsek, nebo provést shlukovou analýzu.
Protože je výsledný model naučen na upravená data, vyplývá z toho, že stejnou úpravu dat je třeba provádět i ve fázi predikce. Pokud má predikce probíhat v reálném čase, musí být úprava dat dostatečně rychlá a je třeba s tímto faktem počítat už ve fázi návrhu a učení modelu.
„Big Data“
Je to fenomén dnešní doby. Termínem „big data“ se rozumí taková data, která svým rozsahem či složitostí přesahují možnosti standardních výpočetních prostředků. Pro jejich analýzu a zpracování je třeba mít k dispozici specializované funkce, které s takovým rozsahem dokáží pracovat. Aplikace v oblasti strojového učení se s problematikou rozsáhlých dat často setkávají, kdy se jedná o velké množství prediktorů či celkovou komplexnost dat přesahující možnosti jednoduchých parametrických modelů.
MATLAB poskytuje celou řadu prostředků, jak s rozsáhlými daty pracovat. Od diskových proměnných a datastore funkcí přes distribuovaná data, paralelní a GPU výpočty až po zpracování obrazu po blocích či streamovací algoritmy. Mezi nejnovější možnosti patří podpora platformy Hadoop a Spark.
Distributor produktů společnosti MathWorks v České republice a na Slovensku:
HUMUSOFT s. r. o.
http://www.humusoft.cz
![]()
![]()