 Sciencemag.cz
Sciencemag.cz

Doporučujeme



Analýza 7 evropských jazyků ukázala, že v jejich psané formě se použití interpunkce řídí stejným statistickým rozdělením. Do interpunkce vědci z Ústavu jaderné fyziky Polské akademie věd v Krakově započítávali 10 „oddělovačů“ – tečku, tři tečky, čárku, středník, pomlčku, otazník, vykřičník, dvě závorky a uvozovky.
Zkoumaly se dva soubory textů. Hlavní analýzy týkající se interpunkce v rámci každého jazyka byly provedeny na 240 populárních literárních dílech napsaných v sedmi hlavních západních jazycích (angličtina, němčina, francouzština, italština, španělština, polština a ruština). Každá kniha obsahovat alespoň 1 500 sekvencí oddělených interpunkčními znaménky.
Nový výzkum vedle statistik samotné interpunkce ukazuje, co s ní děje při překladu literatury. Pro sledování stability interpunkce v překladu byl připraven samostatný soubor obsahující 14 děl, z nichž všechna byla k dispozici v každém ze zkoumaných jazyků.
Pozornost vědců se zaměřila především na statistické rozložení vzdálenosti mezi po sobě jdoucími interpunkčními znaménky. Brzy se ukázalo, že ve všech studovaných jazycích ji nejlépe popisuje jedna z přesně definovaných variant Weibullova rozdělení.
Křivka tohoto typu má charakteristický tvar: nejprve rychle roste a poté, co dosáhne maximální hodnoty, klesá poněkud pomaleji až k určité kritické hodnotě, pod níž s malou a stále klesající dynamikou dosahuje nuly. Weibullovo rozdělení se obvykle používá k popisu jevů přežití (např. populace v závislosti na věku), ale také různých fyzikálních procesů, např. rostoucí únavy materiálů.
Byly patrné určité rozdíly v rozdělení mezi jednotlivými jazyky, které však spočívají pouze ve volbě mírně odlišných hodnot parametrů rozdělení, specifických pro daný jazyk.
Každopádně se s délkou, po kterou dané znaménko dosud nebylo použito, dalo dobře odhadovat, s jakou pravděpodobností se následně objeví. Tato křivka (hazard function) byla opět pro každý jazyk charakteristická.
Jazykem, který se vyznačuje nejnižším sklonem k používání interpunkčních znamének, je angličtina, přičemž španělština následuje s nevelkým rozdílem; slovanské jazyky interpunkci používají nejvíc.
Výjimkou se ukázala být němčina. Příslušná funkce jako jediná protíná většinu křivek sestrojených pro ostatní jazyky (viz obrázek). Zdá se tedy, že německá interpunkce v sobě spojuje interpunkční rysy mnoha dalších jazyků.
Výše uvedené pozorování koresponduje s další analýzou, jejímž cílem bylo zjistit, zda a jak se interpunkční rysy původních literárních děl projevují i v jejich překladech. Podle očekávání se ukázalo, že jazykem, který nejvěrněji transformuje interpunkci z jazyka originálu do cílového jazyka, je němčina.
Zajímavé na tom, je, že interpunkce a její pravidla se jako součást psaného textu objevily poměrně pozdě. Samozřejmě usnadňuje porozumění textu i rychlost čtení. Do současné podoby se kvůli zjevným výhodám používání interpunkce proto mohlo vyvinout velmi rychle. Současně se ale nedá říct, že by platilo, že „čím více interpunkce, tím delší vývoj, tím větší optimalizace“ (apod.). V angličtině a španělštině je podle tohoto výzkumu interpunkce nejméně, přitom jde o jazyky nejpoužívanější, sotva „nejméně optimalizované“. Pravděpodobné vysvětlení zní, že tyto jazyky jsou z hlediska stavby věty natolik formalizované, že je v nich méně prostoru pro dvojznačnost, kterou by bylo třeba řešit interpunkčními znaménky.
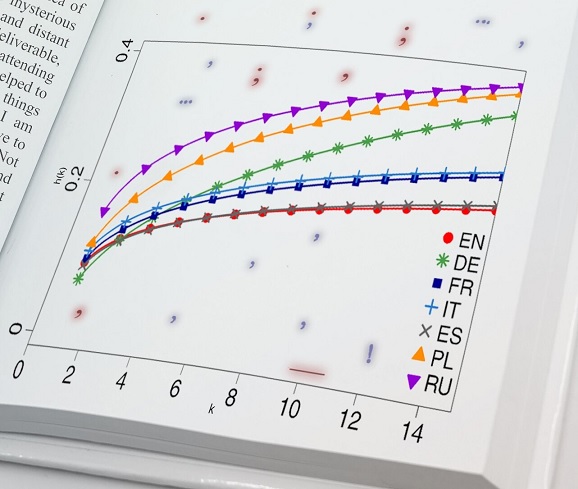
Pravděpodobnost výskytu interpunkčního znaménka v závislosti na délce textu, kde se prozatím neobjevilo. Křivka pro němčinu, která se liší od ostatních zkoumaných jazyků, je zeleně. Credit: Source: IFJ PAN.
Tomasz Stanisz et al, Universal versus system-specific features of punctuation usage patterns in major Western languages, Chaos, Solitons & Fractals (2023). DOI: 10.1016/j.chaos.2023.113183
Zdroj: Henryk Niewodniczanski Institute of Nuclear Physics Polish Academy of Sciences / Phys.org
Poznámky PH:
Ad výčet znamének výše: s těmi závorkami nevím, tam jsou navíc jasně svázaná dvě různá znaménka. V češtině též uvozovky dole a nahoře, tam by to mohlo být podobně složitější.
Jak to celé souvisí s pracovištěm autorů, jadernou fyzikou? Zřejmě podobně jako u nás, kdy součástí příslušné fakulty na ČVUT je také matematické inženýrství. Viz také jiný příspěvek vědců z krakovského pracoviště, též zrovna ne tak docela o jaderné fyzice: Všechna pohoří si jsou podobná – matematicky
Jinak publikace vyšla v Chaos, Solitons & Fractals. Má navazovat na předchozí výzkum o fraktální povaze jazyka vhledem k délkám vět atd.
V souvislosti se statistickým charakteristikami jazyka se asi nejčastěji zmiňuje, že frekvence jednotlivých slov odpovídají Zipfovu zákonu (mocninné rozdělení; několik slov velmi frekventovaných, čím dál větší množství méně často…). Tím se ovšem charakterizují i různé biologické systémy, ekologické i umělé sítě atd.

Jenom dotaz: polštinu a ruštinu zařadili autoři mezi západní jazyky (v rámci Evropy)?
temer jiste ano…